

 2020-02-05 11:03:54
2020-02-05 11:03:54
Hadoop最早起源于google的三大论文GFS,MapReduce和BigTable。后来出现了Java版本的 HDFS、MapReduce 和 HBase,这就是Hadoop。而且,随着Hadoop成为Apache的顶级项目,外围出现了越来越多的组件,这些构成了一个庞大的Hadoop生态圈。
要使用Hadoop,首先要进行安装。Hadoop可以安装在windows操作系统上,但更多的是安装在Linux系统上。因为服务器90%以上都是Linux系统。下面,我们以Centos6为例,看看Hadoop是如何安装的。
安装Hadoop的前提,首先要安装好Java,建议Java8版本。其次要安装SSH,这两点有Linux基础的朋友想必都很熟悉了,我们就不赘述了。
从大的分类上来讲,Hadoop安装模式有三种:单机模式(Standalone)、伪分布式(Pseudo-Distributed)和完全分布式(Fully-Distributed)。前两者只适合测试使用,完全分布式才应用于真正生成环境中。这里,我们只看完全分布式的安装。
集群的安装部署规划如下表所示:
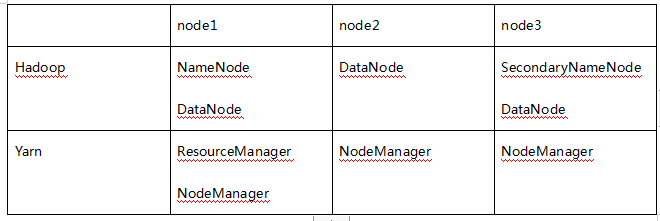
第一步,从官网下载Hadoop安装包。本文下载的是hadoop-2.7.2.tar.gz。上传到node1节点并解压。
第二步,Hadoop文件配置
A. core-site.xml,文件内容如下:

B.hadoop-env.sh,配置JDK的安装配置

C.hdfs-site.xml

第三步,yarn配置文件
yarn-env.sh

yarn-site.xml

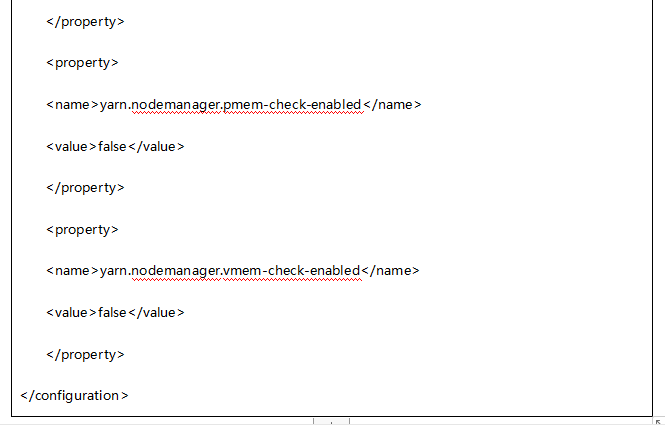
第四步,配置slaves文件
在此文件中,配置DataNode所在节点位置。

第四步,文件分发
在一个节点node1上配置完成后,使用scp命令将hadoop分发到其他节点。

完成以上配置步骤后,即可启动集群进行测试。




 [2023-08-17]
[2023-08-17] 735
735








