

 2021-09-28 14:22:04
2021-09-28 14:22:04
在原生js中我们会经常操作dom结构,通过获取具体标签进行操作,那我们知道常用的js获取元素的方式有哪些吗,并且这些方法之间的区别是什么呢,以及有哪些注意点呢!接下来我们就一起看一下吧!
JavaScript获取元素的的几种方式以及区别
(1) 通过ID名获取getElementById(“id名”):
通过id名是获取具体的实际的一个标签,是静态获取,即获取的时候有就可以获取得到,后续再添加该id名的标签也获取不到了。为何会说通过id名获取是静态获取呢,我们通过具体的例子来看:
- <ul id="list"></ul>
Js代码为:
- var oUl = document.getElementById("list");
- var byId = document.getElementById("h");
- console.log(byId);
- //在ul中添加一个li
- oUl.innerHTML = "<li id='h' style='width:100px;height:100px;background:red'></li>";
- console.log(byId);
最后的结果为:null null
可以得出结论通过id名的获取是静态获取,在后期添加的获取不到
注意:
① 上下文必须是document,至于原因我们留到最后再解释;
② 通过id只获取到一个元素,毕竟id是独一无二的;
③ 通过id获取是静态获取;

(2) 通过name属性获取 getElementsByName('name属性值')
当我们的标签有name属性时,可以通过其name属性来获取标签,如在单选按钮中
- <input type="radio" name='sex' >男
- <input type="radio" name='sex' checked>女
Js代码为:
- var oSex = document.getElementsByName('sex');
- console.log(oSex);
结果如下图是节点列表,为一个类数组:
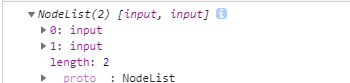
注意:
① 上下文必须是document;
② 获取的结果是一个类数组,不是一个真正的数组,有length属性,可以通过具体的下标获取对应的元素;
(3) 通过标签名获取:getElementsByTagName('标签名')
通过标签名获取的元素是一个元素集合,为类数组形式,有length属性;且通过标签名获取为动态获取,即获取的时候没有该标签,若后续进行手动添加后也能获取到。举例:
- <ul id="list"></ul>
Js代码如下:
- var oUl = document.document.getElementById("list");
- var byTagName = document.getElementsByTagName("li");
- console.log(byTagName);
- //在ul中添加一个li
- oUl.innerHTML = "<li id='h' style='width:100px;height:100px;background:red'></li>";
- console.log(byTagName);
最后的结果为:

可以看到在手动添加li标签之后,可以动态地获取到添加之后的标签,但是我们也看到了通过标签名获取的元素是一个集合,就算只有一个元素也是一个集合,是以一个类数组的形式存在,并不是真正的数组。
注意:
① 上下文可以是document,也可以是一个父元素;
② 是一个类数组,有长度属性,通过[]可以获取具体的某一项;
③ 在使用时要通过具体的下标,比如添加点击事件时;
(4) 通过类名获取 getElementsByClassName(‘类名’)
通过类名获取元素的方式与用法基本一样,也是动态获取;
注意:
① 上下文可以是document,也可以是一个父元素;
② 是一个类数组,有长度属性,通过[]可以获取具体的某一项;
③ 在使用时要通过具体的下标,比如添加点击事件时;
④ 注意单词拼写,因为class是一个关键字,所以为getElementsByClassName
(5) 快速获取html元素 document.documentElement
- document对象有一个documentElement属性,该属性始终指向HTML页面中的<html>元素。
- var html = document.documentElement; //取得对<html>的引用
(6) 快速获取body元素 document.body
- document 对象还有一个 body 属性,直接指向<body>元素。
- var body = document.body; //取得对<body>的引用
(7) 通过选择器获取一个元素 querySelector("css选择器")
该方法接收一个 CSS 选择符,返回与该模式匹配的第一个元素。
注意:
① 上下文可以是document,也可以是一个父元素;
② 参数是选择器,如“div .active”;
③ 返回值只能获取到第一个元素;
④ 与通过id获取的方式一样为静态获取;
⑤ Ie8以下存在兼容问题;
(8) 通过选择器获取一组元素 querySelectorAll("css选择器")
该方法接收一个 CSS 选择符,返回的是所有匹配的元素而不仅仅是一个元素。其结果为一个节点列表。
注意:
① 上下文可以是document,也可以是一个父元素;
② 参数是选择器,如“div .active”;
③ 返回值为一组节点列表,是一个类数组;
④ 与通过id获取的方式一样为静态获取;
⑤ Ie8以下存在兼容问题;
使用原生JS获取DOM元素的8个方法讲完了,接下来在讲一下为什么有的方法只能在document上使用。
拿div举例子,div是HTMLDivElement类的一个实例,document是HTMLDocument 的实例。
他们的继承关系:
HTMLDivElement > HTMLElement > Element > Node > EventTarget
HTMLDocument > Document > Node > EventTarget
我们都知道子类继承父类,子类就可以使用父类的属性和方法。他们相同的继承关系是Node和EventTarget,也就是说他们都可以使用Node和EventTarget上的方法。
如Node上的nodeName、parentNode等,和EventTarget上的addEventListener等。
getElementById只在Document类的原型上,HTMLDivElement 没有继承Document类,所以div不能使用getElementById方法。
getElementsByTagName即在Document类的原型上也在Element类的原型上,所以div和document都可以使用getElementsByTagName方法。其它同理。




 [2022-08-03]
[2022-08-03] 484
484





