

 2020-11-27 11:34:45
2020-11-27 11:34:45
在chrome浏览器输入:chrome://extensions/,如图1所示。

图1 Chrome的扩展程序
在上面的界面中直接将XPath-Helper_v2.0.2.crx拖动至该扩展程序页面,点击确定即可。如果安装失败,弹框提示:无法从该网站添加应用、扩展程序和用户脚本,则打开开发者模式,将crx文件后缀修改为rar,并解压成文件夹,点击开发者模式中的加载已解压的扩展程序按钮,选择解压后的文件夹,点击确定,安装成功。安装完这个插件的Chrome浏览器见图2。其中XPath-Helper插件的图标是黑底方框内部为白色x。
图2安装了扩展程序的Chrome
安装了XPath_Helper后,下面介绍一下XPath_Helper的用法。鼠标点击XPath_Helper的图标,然后在Chrome浏览器中上面部分就弹出了XPath_Helper界面。这时,用户可以按住shift,把鼠标悬停在想要抓取的HTML页面元素上,则在XPath_Helper界面左侧窗口中显示出这个HTML页面元素带属性的XPath绝对路径,而右侧窗口显示出该HTML页面元素的内容。具体如图3所示。

图3 XPath_Helper使用
下面采用XPath_Helper分析一下百度贴吧网站。击XPath_Helper,获得网页上的各种元素的XPath信息。
首先,获取lol吧的关注数量,按住shift,鼠标悬停在关注数量上,则XPath_Helper中得到了该HTML元素的XPath路径:
/html/body[@class='skin_normal']/div[@class='wrap1']/div[@class='wrap2']/div[@class='header']/div[@id='pagelet_frs-header/pagelet/head']/div[@class='head_main']/div[@class='head_content']/div[@class='card_top_wrapclearfixcard_top_theme']/div[@class='card_topclearfix']/div[@class='card_title']/div[@class='card_num']/div[@id='pagelet_forum/pagelet/forum_card_number']/span/span[@class='card_menNum']
这是个绝对路径,从网页的根目录开始,一般在编写爬虫程序时,这个路径太长,不建议使用,可以用带有唯一属性的XPath相对路径表示该元素,这时在XPath_Helper左侧的框中修改XPath绝对路径,思路是在Chrome开发工具的Elements中观察这个元素对应的HTML源代码,如果这个标签带有类(class)属性,则一般用这个代表该元素。例如把上述绝对路径改为//span[@class='card_menNum'],在XPath_Helper右侧的结果框中依然得到关注数:12,913,346,则表明采用的XPath相对路径是有效的,在写爬虫代码时,采用这个相对路径,即可找到该元素。
图4展示了采用XPath相对路径找到lol吧的关注数量的结果页面。

图4 获取百度lol贴吧的关注数量
下面想获得lol贴吧置顶帖子的标题这个信息,具体见图5展示出的部分。这时发现采用XPath_Helper较难同时获得这3个置顶帖子的XPath路径,带了属性的标签很长,看着有点晕。不要怕,采用Chrome开发工具中的“小箭头”(即在网页中选择一个元素并查看它)来解决类似的问题。先点起这个按钮,然后把鼠标悬停到想要查看的元素上,这时在Elements窗口中这个元素对应的HTML源码被高亮了,接着右键单击这个高亮块,在弹出菜单中选择Copy,并在子菜单中选择CopyXPath。然后把得到的内容拷贝到XPath_Helper的左侧窗口中,则右侧窗口中得到了对应的内容。这时,XPath_Helper左侧窗口中的内容是//*[@id="thread_top_list"]/li[2]/div/div[2]/div/div[1]/a。接下来采用上面同样的方法获得其他置顶帖子标题的XPath相对路径,并仔细观察这几个路径。发现不同之处在于被反斜杠划分出的第二部分li标签中括号中的数字分别是1、2、3。这时可知这几个置顶帖子是存放在id为thread_top_list这个大的ul标签中,且被不同的li标签包含着,所以把li标签的中括号数字去掉,这时就能对应上所有的置顶帖子标题,具体如图5所示。
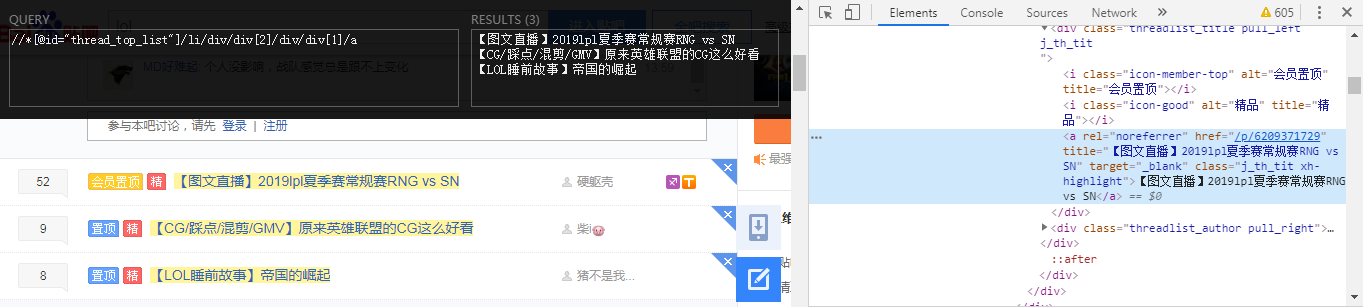
图5 获取百度lol贴吧的置顶帖子信息
如果对Python开发感兴趣或者想要深入学习的现在可以免费领取学习大礼包哦(点击领取80G课程资料 备注:领资料)。




 [2023-08-17]
[2023-08-17] 656
656






