

 2021-10-29 14:50:16
2021-10-29 14:50:16
编程语言中的正则表达式用于描述搜索模式的特殊文本字符串。这对于从文本(如代码、日志、文档、电子表格等)中提取信息非常有用。使用正则表达式时,首先要认识到的是,所有内容本质上都是一个字符。ASCII或拉丁字母是键盘上的字母,Unicode用于匹配外来文本,它包括数字和标点符号以及所有特殊字符,如$、#、@、!、%等。
例如,正则表达式可以告诉程序从字符串中搜索特定文本,然后相应地打印出结果。正则表达式可以包括文字匹配、重复、分支、模式组成等。
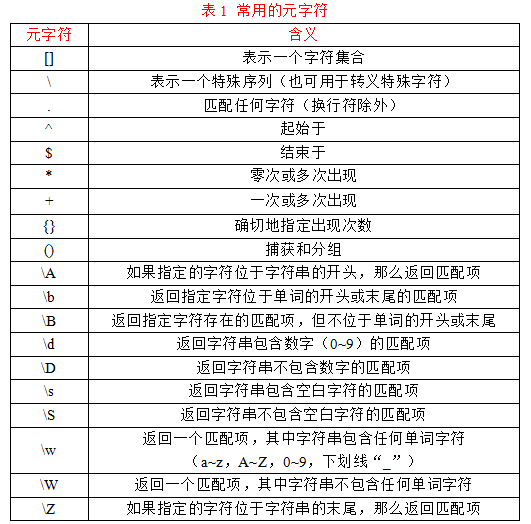
在Python中,正则表达式通过re模块导入。元字符是具有特殊含义的字符,用来匹配特定文本。常用的元字符如表所示。
re模块中定义了一些函数,分别对应不同的匹配模式。
findall()函数用于返回包含所有匹配项的字符串列表:
- >>> import re # 导入re模块,以下示例都将省略这行代码
- >>> s = 'hello 12 hi 89. How 34'
- >>> pattern = '\d+' # 匹配数字
- >>> result = re.findall(pattern, s)
- >>> print(result)
- ['12', '89', '34']
split()函数用于在存在匹配项的情况下拆分字符串,并返回发生拆分的字符串列表:
- >>> s = 'python:234, java 90' # 将数字作为分隔符
- >>> pattern = '\d+'
- >>> result = re.split(pattern, s)
- >>> print(result)
- ['python:', ', java ', '']
如果不存在匹配项,那么split()函数返回一个包含空字符串的列表。可以将maxsplit参数传递给split()函数,maxsplit代表最大拆分次数:
- >>> s = 'python:234, java 90'
- >>> pattern = '\d+'
- >>> result = re.split(pattern, s, 1) # 分割最大值是1,即拆成两份
- >>> print(result)
- ['python:', ', java 90']
sub()函数用于返回一个字符串,其中匹配到的匹配项被替换变量的内容替换:
- >>> s = 'abc 12\
- ... de 23 \n f45 6'
- >>> pattern = '\s+' # 匹配空白字符
- >>> replace = '' # 用空字符串替换匹配项
- >>> new_string = re.sub(pattern, replace, s)
- >>> print(new_string) # 完成替换
- abc12de23f456
如果不存在匹配项,那么sub()函数返回原始字符串。
subn()函数与sub()函数类似,只不过subn()函数返回一个包含2个项的元组,其中包含新字符串和进行替换的次数:
- >>> s = 'abc 12\
- ... de 23 \n f45 6'
- >>> pattern = '\s+'
- >>> replace = ''
- >>> new_string = re.subn(pattern, replace, s)
- >>> print(new_string)
- ('abc12de23f456', 4)
search()函数采用两个参数,分别是匹配模式和字符串。该函数查找正则表达式模式与字符串匹配的第一个位置。如果匹配成功,那么search()函数返回一个match对象;否则返回None:
- >>> s = 'Python is fun'
- >>> match = re.search('\APython', s) # 检查'Python'是否在开头
- >>> print(match) # 返回一个对象
- <_sre.SRE_Match object; span=(0, 6), match='Python'>
上面的match变量包含着match对象,match对象的re属性返回一个正则表达式对象,string属性返回传递的字符串:
- >>> match.re
- re.compile('\\APython')
- >>> match.string
- 'Python is fun'




 [2023-08-17]
[2023-08-17] 656
656






